PCANet A Simple Deep Learning Baseline for Image Classification?
更新日期:
级联PCA filters Network,这篇paper让我们反思层次结构的重要性,也是DL的核心理念。
Abstract:
- 基于PCA的DL Network
- PCA + binary hashing + block-wise histograms
- PCA 是滤波器
- RandNet LDANet : 拓扑结构同PCANet, but cascaded filters are either selected randomly or learned from LDA
- 数据集:LFW and MultiPIE(face), MNIST, Extended Yale B, AR, FERET datasets(face)
- PCANet在texture classification, object recognition效果比较好
Introduction
人工设计的底层特征在不同的task适应性不够强。因此一个改进的方法就是像DNN那样从数据中学习底层特征,高层特征能够代表更加抽象的意义特征。DL结构的重要部分是卷积,一般由卷积+nolinear+pooling组成。学习卷积层的方法有RBM、regularized autoencoders。一般网络学习方法为SGD,然而想要学习到好的网络十分依赖于调参和trick的技巧。
现有的DL变种ScatNet与CNN的唯一区别是把卷积换成了小波,所以他不用学习,而且效果不赖(宣称在一些数据集上性能优于CNN和DNN)。
Motivations,我们想要实现两个目的:
- 希望训练一个简单的网络去学习数据
- 提供一个baseline为人们做更为复杂的结构
用PCA代替卷积层,非线性层用哈希二值量化,pooling用block-wise histograms。
底层中不用nolinear操作,高层才用,但性能依然不错。
contributions
实验效果证实了cascaded feature learning or extraction architectures有助于效果的提升。还从数学上分析的他的性能。
Cascaded linear networks
Structures of PCANet
只有PCA filter是要学习的参数。
first stage
分成$ k1 \times k_2 $个patch。令$ \bar{X}{i}=\left[\bar{x}{i,1},\bar{x}{i,2},\cdots,\bar{x}{i,mn}\right] $其中$ \bar{x}{i,n} $为第i幅图像的第n个patch减去均值后的向量。
用$ X=\left[\bar{X}{1},\bar{X}{2},\cdots,\bar{X}{N}\right]\in\mathbb{R}^{k_1k_2\times{Nmn}} $表示所有图像patch。
然后求解PCA filter:
$$\min{V\in\mathbb{R}^{k1k_2 \times L_1}}||X-VV^TX||^2_F,~s.t.~V^TV=I_L$$
如此就得到filters $ W^1_l=mat{k1,K_2}(q_l(XX^T))\in\mathbb{R}^{k_1 \times k_2} $ mat是一个映射函数从$ v\in\mathbb{R}^{k_1k_2} $到$ W\in\mathbb{R}^{k_1 \times k_2} $,$ q_l(XX^T) $表示第$l$个主特征向量。这里滤波器数目为$L_1$。将输入图像表示为$ {\mathcal{I}_i}^N{i=1} $。
second stage
卷积$\mathcal{I}1$,做了0-Padding以使得$ \mathcal{I}_1 $和$ \mathcal{I}_2 $有相同的size
$$ \mathcal{I}^l_i=\mathcal{I}_i\ast W^k_l,i=1,2,\cdots,N $$ 注意:相当于卷积,此时特征数目为$N \times L_1$
$$ W^2_l=mat{k1,K_2}(q_l(YY^T))\in\mathbb{R}^{k_1 \times k_2} $$
与第一步操作相同。
这一步操作可以表示为:
$$ \mathcal{O}^l_i={\mathcal{I}^l_i\ast W^2_l}^{L_2}{l=1} $$ 注意:相当于卷积,$\mathcal{O}$是输出“图”,此时特征数目为$N \times L_1 \times L_2 $
Output stage: hashing and histogram
输出通过阶跃函数并2→10进制转换,$L2$是滤波器数目
把输出数据二值化后转换成十进制数这时T相当与一副image,每个像素点的范围是[0,$2^{L_2-1}$],每一个T可以作为一个word。
$$ T^l_i=\sum^{L_2}{l=1}2^{l-1}H(I_i\ast W^k_l)$$ 注意:这里特征数目为$N \times L_1$
对每个的image($L_1$个)的T我们计算直方图。则输入图像的特征可以表示为Bhist(分成8个块)
$$f_i=\left[Bhist(T^1_i),Bhist(T^2_i),\cdots,Bhist(T^{L_i}_i)\right]^T\in\mathbb{R}^{(2^{L_2})L_1B}$$ 注意:此时输出特征数目为$N$
我们通过实验发现block重叠时适合数字,纹理和对象的识别,不重合时适合人脸识别。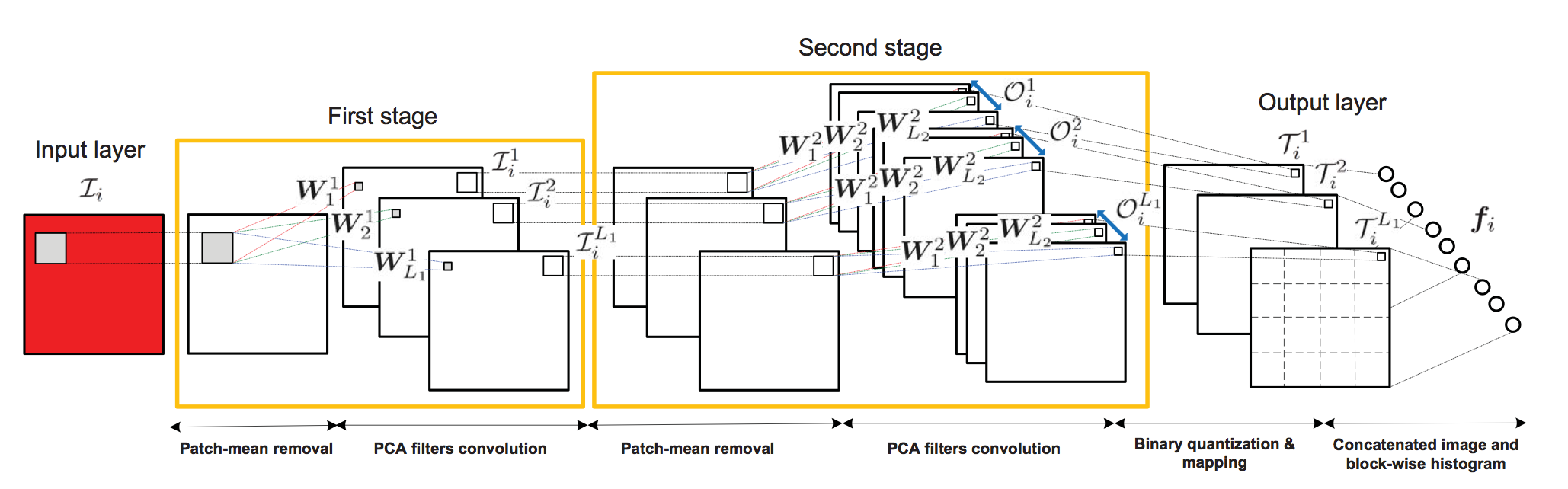
实验中$L_1=L_2=8$
Comparison with ConvNet and ScatNet
去均值相当于CNN中的local contrast normalization。PCA可视为最简单的auto-encoder(最小化reconstruction error)
PCANet没有非线性层,作者试过加absolute rectification layer但没有效果。原因可能是量化和输出层的local histogram已经引入了足够的sufficient invariance and robustness。
同样多的filer数目两层的比单层的好。
比较实验证明的多层的结构能够更好的学习语意信息。
Computational complexity
$$\mathcal{O}(mnk_1k_2(L_1+L_2)+mn(k_1k_2)^2)$$
Conclusion
PCANet不会代入规则化的参数,不需要数值优化的解。他的数学分析以及复杂性得以减轻。PCANet 性能胜过 RandNet and LDANet, 与ScatNet和CNN性能相当。
对于解决图像分类的DL的结构研究来说,PCANet是一个简单有价值的Baseline,但在ImageNet还不够好。更复杂filter或更深层次的网络结构可能可以提升他的性能。
目前的瓶颈是PCANet的维度会随着特征的增加指数增长,一种改进的方法是把2维卷积改成tensor-like filters,我们将在剩下的工作中进一步研究。